Fundamentals of Version Control
Before diving into data and model versioning in ML, let’s brush up on some general key concepts of version control. We’ll cover the definition of version control, a few central terms, why version control is useful, and the three types of version control.
What is Version Control?
Version control describes tracking and managing changes made to files or project folders over time.
Some key concepts of version control are:
-
Version: A snapshot of a file or project at a specific time.
-
Repository: The location where all the versions of a file or project are stored.
-
Commit: The process of saving a new version of a file or project to the repository.
-
History: The history of changes made to a file or project, including information about who changed what when (and optionally why it was changed and what the impact was).
Why Do You Need Version Control?
The use of version control goes beyond saving different versions of a file or project. Its main advantages are traceability, reproducibility, rollback, debugging, and collaboration.
-
Traceability: You can quickly get an overview of who changed what and when with the history log and, ideally, see the impact of a change.
-
Reproducibility: Knowing which version of a file or a project was used at a specific time can help reproduce past results.
-
Rollback: You can switch between different versions quickly. This is helpful for rollback because you can revert to an earlier stable version if something goes wrong.
-
Comparison & Debugging: You can compare different versions and see what changed between any two versions, e.g., two releases. This is helpful for debugging.
-
Collaboration: Depending on the type of version control (see Types of Version Control), it can enable collaboration in teams. Contributors can create copies of a project’s snapshot (branching) and share their changes after successful testing with the overall project (merging).
Types of Version Control
Version control comes in various shapes with its advantages and disadvantages. Although you can manually version your files, using a version control system is standard practice. We differentiate three types of version control systems: local, centralized, and distributed.
Does the below picture look familiar to you? When we need to differentiate between different versions of a file for the first time, we intuitively store the same file under different names to distinguish the different versions from each other.
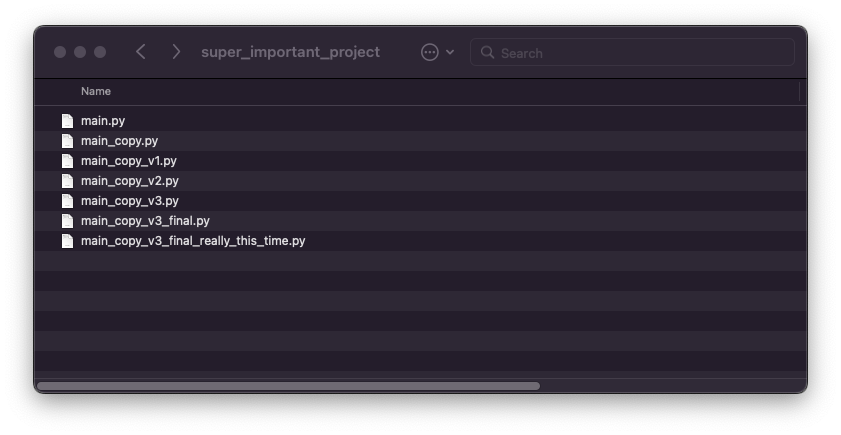
Manual version control has only one advantage (it’s rather easy) and many drawbacks (oh so many). While this type of version control requires no setup effort, it is difficult to understand the history of changes, leaving little possibility for collaboration with others. If your disk is damaged, all changes will be lost.
That’s why it is standard practice to use version control systems instead of manually versioning files and projects.
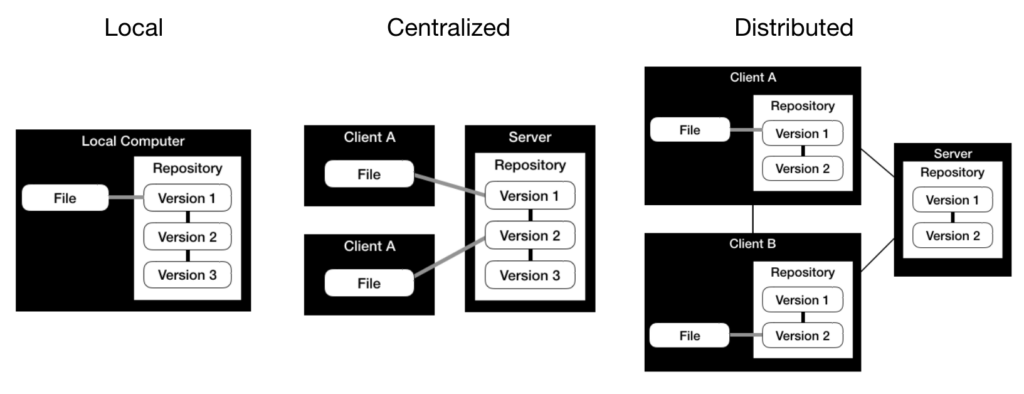
We differentiate between 3 types of version control systems, which are visualized below:
-
Local Version Control Systems: You have one repository on one local computer. The advantages are simple setup and use without requiring a network connection. But the lack of a central repository doesn’t allow for collaboration, and it has limited backup capabilities (single point of failure).
-
Centralized Version Control Systems: You have one repository on a central server. Versions are stored directly in this central repository. The central repository enables collaboration. But it requires a network connection to the central repository, which is also a single point failure regarding backup capabilities. An example of a centralized version control system is Subversion.
-
Distributed Version Control Systems: You have one repository on a central server. Clients make local copies of the central repository. Versions are first stored in the local repository and later synchronized with the central repository. The central repository enables collaboration, and the local copies enable offline work and have improved backup capabilities. But a local copy of the full repository also requires more disk space. Examples of distributed version control systems are Git or Mercurial.
Version Control in Machine Learning
Version control is not only useful in software development but in the development process of ML models as well. In ML, versioning source code is as important as versioning artifacts like datasets and models.
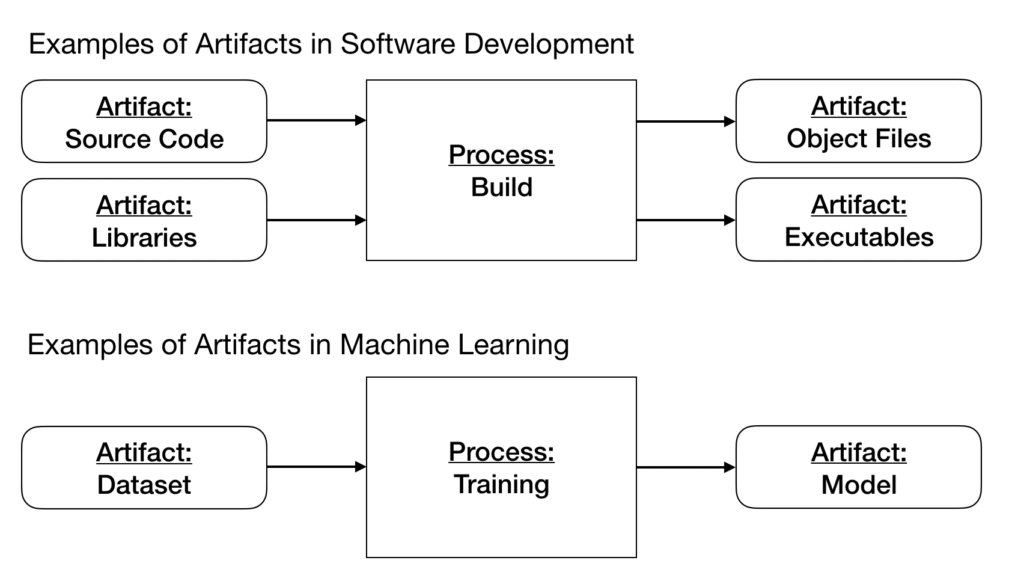
During the development process of an ML model, we create artifacts other than source code. An artifact is any file that is an input or an output of a process. Examples of artifacts in software development that inputs are source code and libraries as inputs of a process. In contrast, object files and executables are example artifacts that are outputs of a process. In this example, the process is a build process.
In ML, the most important artifacts are datasets and models. For example, a dataset would be an artifact that is an input of a training process, while a model would be an artifact that is an output of it.
The following sections cover version control for datasets and ML models. The core concept here is similar between common version control and data and model version control. Instead of repeating the concepts of traceability, reproducibility, rollback, debugging, and collaboration for data and models in place of source code, we will focus on when data and models change and need to be versioned.
Data Version Control
While version control is typically associated with source code, model version control or model versioning specifically indicates the version control of data in ML. It describes the practice of storing, tracking, and managing the changes in a dataset.
A new version of a dataset can be stored for the following events during the model development process:
-
Data preprocessing (data content changes) such as data cleaning, outlier handling, filling of missing values, etc.
-
Feature engineering (data becomes “wider”) such as aggregation features, label encoding, scaling, etc.
-
Dataset splits (data is partitioned) typically mean dividing your data into training, validation, and testing data.
-
Dataset update (data becomes “longer”) when new data points are available.
Model Version Control
Similarly to how data versioning indicates the version control for data in ML, model version control or model versioning specifically indicates the version control of ML models. It describes the practice of storing, tracking, and managing the changes in an ML model.
For model version control, we need to define two more terms to differentiate from the term “model version” [2].
-
Model version: single snapshots of a trained model (e.g., model weights after a cross-validation fold)
-
Model artifact: a sequence of logged model versions (e.g., the collection of the model weights after each fold of a training run)
-
Registered model: a selection of linked model versions (e.g., the candidate models for a task in production)
Registered models are saved in a model registry. You can think of a model registry as a repository for your registered models. While you could use an artifact repository like JFrog’s Artifactory to store your ML models, a model registry is specifically intended for storing and managing ML models, including versioning, lineage, and lifecycle management.
While data version control is mostly relevant for model development, model management, including model version control, applies to the complete model lifecycle from training through staging to production.
-
Model development: During model development, you may want to track different versions of your models, starting from the model selection to the model training with different hyperparameters.
-
Model deployment: During the staging process, you may want to evaluate the performances of different model versions and communicate which models should be used for deployment. Aside from logging different versions, you may want to tag specific versions with aliases (e.g., best or release).
-
Model monitoring: When your model is in production, you may want to monitor its performance.
If you are interested in implementing data and model version control for your ML models, there are various MLOps platforms and tools that incorporate data and model versioning, such as DVC, Neptune, or Weights & Biases.
For a practical guide on how to use W&B Artifacts for data and model versioning in Python, you can watch the below video walkthrough with the accompanying interactive Colab notebook: